CSGO Scraper & Team Rankings
I love Counter Strike. I fell in love with the game in December of 2013 when I was peer pressured into trying Global Offensive during winter break at one of my favorite man caves back home. Coming from years of playing Call of Duty, I couldn’t hit an enemy to save my life (“What do you mean I can’t move and shoot?”) but after logging almost 1000 hours in game, achieving the highest competitive rank possible (yes it was when the ranks were bugged, but who keeps track of that), I can say that I’m at least not terrible.
Alongside my love of playing the game, I also fell in love with watching the game at a professional level. And more importantly, my inner data scientist was alive with excitement. A professional competition where the game takes place entirely on a server means you have perfect knowledge of every action in the game. It’s data heaven.
Turns out, extracting the logs from the server into meaningful data was harder than I thought. I gave it an attempt in grad school.
So I went back to the drawing board and thought what I really want is to capture every game, even if it’s only at a high level. Enter HLTV. The place to go for information on anything Counter Strike related (I swear this isn't a plug). Almost every professional match played is catalogued and analyzed on their website. I thought I had hit the jackpot.
But, HLTV doesn’t provide an API or any easy way to export their vast information. I had just started to undertake web development while working at Deloitte, and I thought I might be able to cobble together a scraper.
Step 1: Scraping the Page
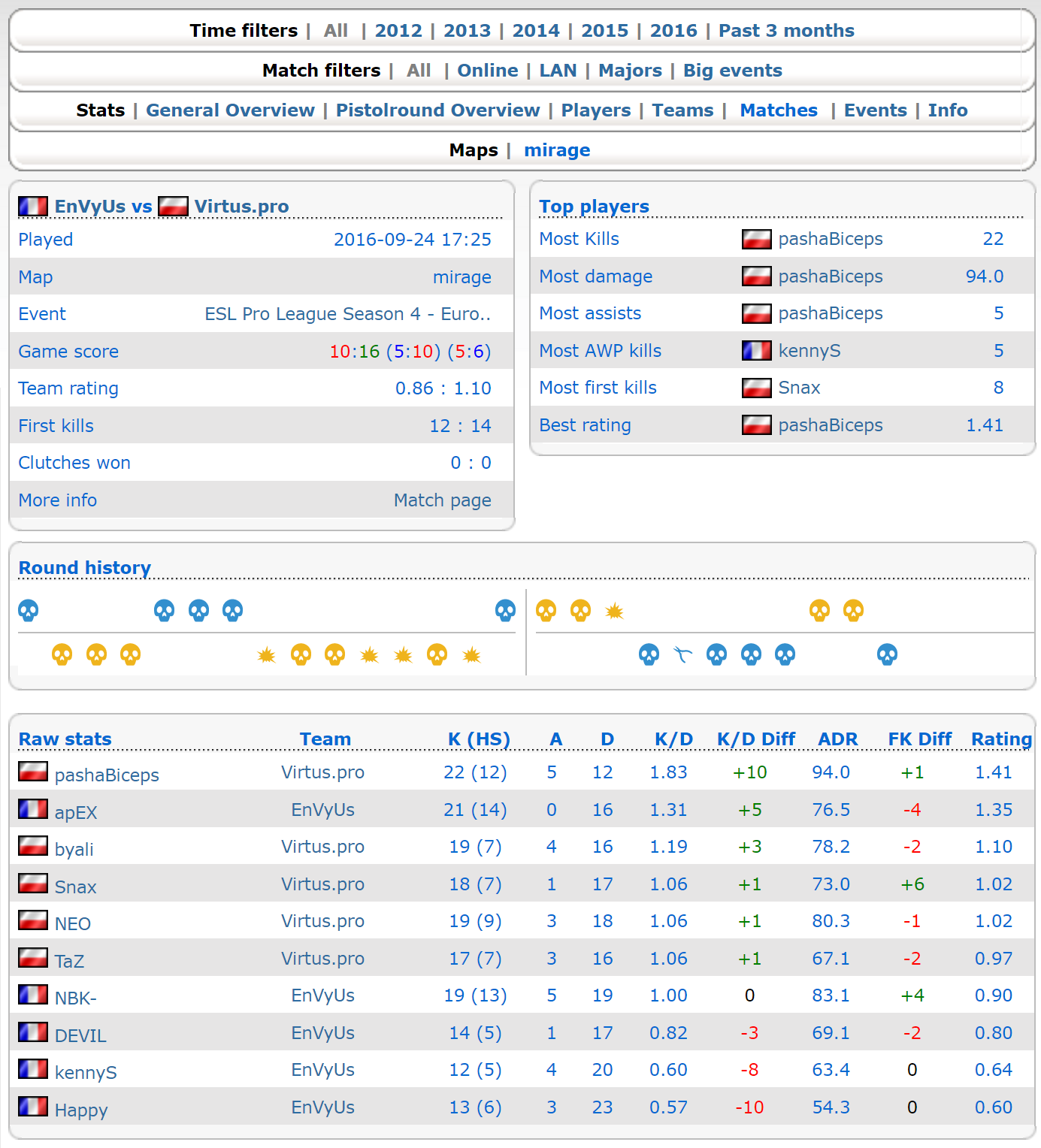
This is exactly what I was looking for. After every game, a page is created with essentially three different sections: Information about the match and how the team performed as a whole, the result of each round played, and stats for each player in the match. The following code, using the java library jsoup, returns the center section of the page pictured above under the variable body.
From there, the rest of the page was fairly straightforward to scrape. Many of the selectors seemed oddly specific, but it appears the page formatting was mostly accomplished using inline styles as opposed to CSS and defined classes.
Great, after flushing out the details to capture the data within each section of the page, I had a scraper. I just had to figure out how to access the page for each match. I looked at the URL:
http://www.hltv.org/?pageid=188&matchid=35822
And figured I could enumerate all values for MatchID at the end of the query string. Turns out, it's not that easy. MatchID seemed to skip values for 'real' matches and would return inconsistent results when specifying a value that didn't exist in their database. So how do I know which MatchIDs correspond to real matches?
Step 0: Find the Golden MatchIDs
I took a step back and realized there was a separate place that contained a list of all matches with their golden MatchIDs, the recent matches.
This page contains a list of completed matches with some additional high-level information and a link to the detailed statistics page. Since I had already figured out the quirks of using jsoup, and this page had such a simple structure, it was pretty straightforward to create a second scraper.
This annoying backtrack turned out to be a blessing in disguise as I worked through the details of executing and maintaining the project. First, I could easily filter out older matches using built in functionality on the recent matches page (who needs games from back in 2012). Second, I could distinguish if a match was played online, at a LAN event, or during a major, which often has a significant impact on a team's performance. Last, as this list is in chronological order, I could easily check and see if their were new matches available to analyze as I periodically updated my database.
Step 2: Storing the Data
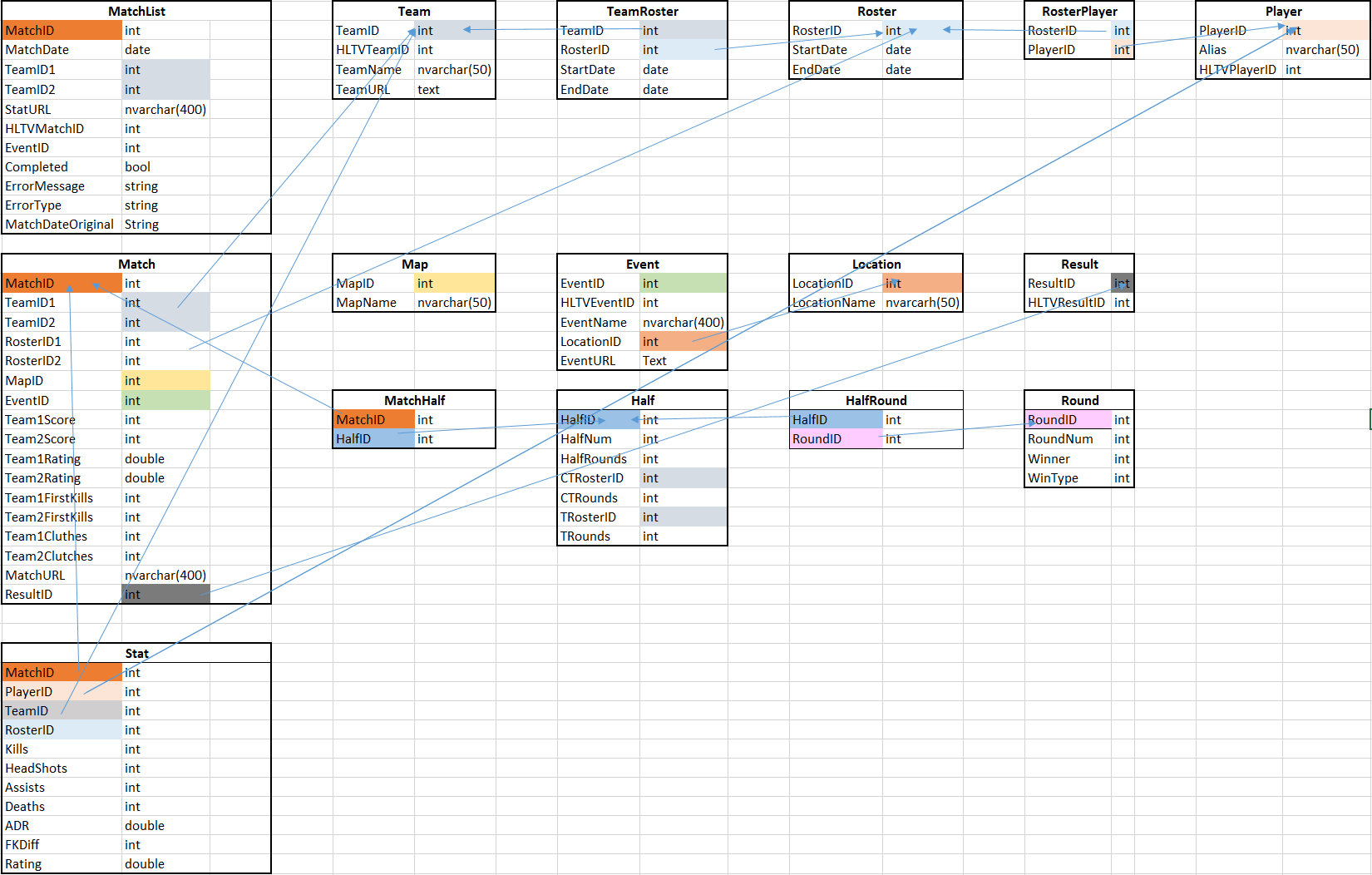
Next, I created a fairly straight forward database schema and implemented it in SQLite using DB Browser for SQLite. Mostly unremarkable, but there were a few things I managed during this data capture phase that made analysis easier in the future.
Players, Rosters, and Teams - If you follow professional Counter Strike, you know that teams modify and swap their rosters all the time. Players get DDOSed and a team needs a stand-in, lineups are bought leading to a change in name, and if a player's performance is subpar, they are replaced before they can even get comfortable. To capture how dynamic these interactions are, I grouped 5 players into a roster indicating their first match played together by StartDate, and their last game played together as EndDate (or NULL if each player's last game played is with the current roster, indicating the roster is active). I used the same mechanism for team (or sponsor) to easily tell which roster was currently active with each team. This way, if a team needs to use a different player (and subsequently a different roster), the match statistics are tracked separately as opposed to being lumped in with all of their results.
Step 3: The Model
Next, I moved to R to create the Elo based model for ranking the teams. I pulled every match played by each active roster and gave the roster a baseline rating of 1300. To determine a team's score in a given game, I took the number of rounds they won over the total number of rounds played. This purposefully rewarded a blowout win with a higher score while a close game (or tie) would result in a score close to 0.5. From there, I divided the matches into a training set containing 80% of the data, and a test set with 20% of the data to find the optimal multiplier for updating a team's ranking after a match based on minimizing the error in the predicted score. Using the optimal multiplier, I began cataloguing the predicted outcome against actual outcomes and found that my model accurately predicted the winner of a match 66% of the time. While this is a promising result (if I were a betting man, I could probably make a fair profit), I hope to improve the model's predictive ability by including more inputs such as the map choice, individual performance, match venue (online matches versus major tournamnets), and fractional rosters to yield even more accurate results.